
06-实战案例
预计学习时间:2.5 小时
难度:⭐⭐⭐⭐
核心内容:端到端完整回测项目,综合运用前面学到的所有知识
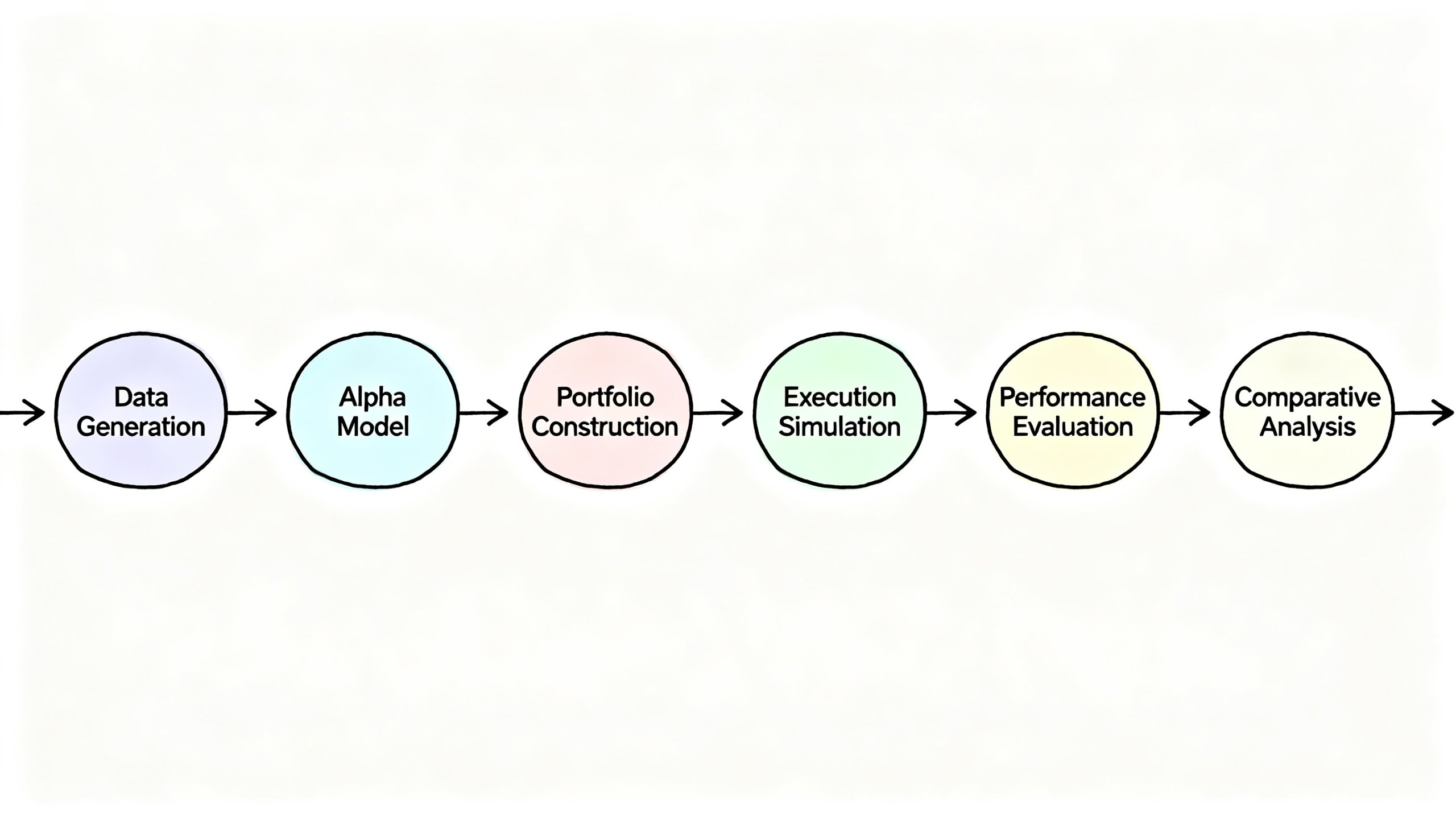
项目概述
本节将构建一个完整的回测系统,包括:
- 生成模拟数据:200只股票 × 3年日频数据
- 构建Alpha模型:使用LightGBM生成预测信号
- 组合构建:对比Top-K等权和IC加权
- 执行模拟:考虑交易成本、T+1限制
- 绩效评估:完整的绩效报告和可视化
- 对比分析:不同方法、不同参数的影响
1. 数据生成
1.1 模拟价格数据
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
# 设置参数
np.random.seed(42)
N_STOCKS = 200
START_DATE = '2021-01-01'
END_DATE = '2023-12-31'
# 生成日期序列(只保留交易日,去掉周末)
dates = pd.date_range(START_DATE, END_DATE, freq='B') # B = 工作日
# 生成股票代码
stock_codes = [f'S{i:04d}' for i in range(N_STOCKS)]
# 生成行业分类
INDUSTRIES = ['金融', '科技', '消费', '医药', '制造', '能源', '材料', '公用']
industry_map = {code: np.random.choice(INDUSTRIES) for code in stock_codes}
# 生成基准收益率(市场因子)
market_return = np.random.randn(len(dates)) * 0.015
# 生成行业因子
industry_returns = {}
for industry in INDUSTRIES:
industry_returns[industry] = np.random.randn(len(dates)) * 0.01
# 生成特质风险
idiosyncratic_return = np.random.randn(len(dates), N_STOCKS) * 0.02
# 计算每只股票的收益率
returns_data = pd.DataFrame(0, index=dates, columns=stock_codes)
for i, code in enumerate(stock_codes):
industry = industry_map[code]
# 股票收益 = 市场收益 + 行业收益 + 特质收益
beta = np.random.uniform(0.5, 1.5) # 市场Beta
industry_beta = np.random.uniform(0.3, 0.8) # 行业Beta
stock_return = (beta * market_return +
industry_beta * industry_returns[industry] +
idiosyncratic_return[:, i])
returns_data[code] = stock_return
# 生成价格数据
initial_prices = np.random.uniform(10, 100, N_STOCKS)
prices_data = pd.DataFrame(0, index=dates, columns=stock_codes)
for i, code in enumerate(stock_codes):
prices_data[code] = initial_prices[i] * (1 + returns_data[code]).cumprod()
# 生成成交量数据(对数正态分布)
volumes_data = pd.DataFrame(
np.random.lognormal(mean=16, sigma=0.5, size=(len(dates), N_STOCKS)),
index=dates,
columns=stock_codes
).astype(int)
print("=== 数据生成完成 ===")
print(f"股票数量: {N_STOCKS}")
print(f"日期范围: {dates[0]} 至 {dates[-1]}")
print(f"交易日数: {len(dates)}")
print(f"\n行业分布:")
for industry in INDUSTRIES:
count = sum(1 for v in industry_map.values() if v == industry)
print(f" {industry}: {count}只股票")
# 显示数据预览
print(f"\n价格数据预览:")
print(prices_data.head())
print(f"\n收益率统计:")
print(returns_data.describe().loc[['mean', 'std']])1.2 生成模拟因子和标签
def generate_factors_and_labels(prices, returns, volumes):
"""
生成模拟因子和标签
因子包括:
- 动量因子:过去20日收益率
- 波动率因子:过去20日波动率
- 换手率因子:成交量变化
- 规模因子:市值的对数
- 价值因子:倒数PE(简化模拟)
标签:未来5日收益率
"""
factors = {}
labels = {}
for code in prices.columns:
# 动量因子:过去20日收益率
momentum = prices[code].pct_change(20)
# 波动率因子:过去20日波动率
volatility = returns[code].rolling(20).std()
# 换手率因子:成交量标准化
turnover = volumes[code].pct_change(5)
# 规模因子:价格对数(简化)
size = np.log(prices[code])
# 价值因子:随机模拟
value = np.random.randn(len(prices)) * 0.1
factors[code] = pd.DataFrame({
'momentum': momentum,
'volatility': volatility,
'turnover': turnover,
'size': size,
'value': value
}, index=prices.index)
# 标签:未来5日收益率
labels[code] = returns[code].shift(-5)
return factors, labels
# 生成因子和标签
factors_dict, labels_dict = generate_factors_and_labels(
prices_data, returns_data, volumes_data
)
# 合并所有股票的因子
all_factors = []
all_labels = []
for code in stock_codes:
df = factors_dict[code].copy()
df['stock'] = code
df['industry'] = industry_map[code]
df['label'] = labels_dict[code]
df['date'] = df.index
all_factors.append(df)
factor_df = pd.concat(all_factors, ignore_index=True)
factor_df = factor_df.dropna()
print(f"\n=== 因子和标签生成完成 ===")
print(f"总样本数: {len(factor_df):,}")
print(f"每只股票平均样本: {len(factor_df) / N_STOCKS:.0f}")
print(f"\n因子统计:")
print(factor_df.describe())2. Alpha模型构建
2.1 数据准备
from sklearn.model_selection import train_test_split
# 准备训练数据
feature_cols = ['momentum', 'volatility', 'turnover', 'size', 'value']
# 划分训练集和测试集(按时间)
train_df = factor_df[factor_df['date'] < '2023-01-01']
test_df = factor_df[factor_df['date'] >= '2023-01-01']
print(f"训练集: {len(train_df):,} 样本")
print(f"测试集: {len(test_df):,} 样本")
X_train = train_df[feature_cols].values
y_train = train_df['label'].values
X_test = test_df[feature_cols].values
y_test = test_df['label'].values2.2 LightGBM模型训练
import lightgbm as lgb
from scipy import stats
# 创建LightGBM数据集
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# 参数设置
params = {
'objective': 'regression',
'metric': 'mse',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': -1
}
# 训练模型
print("\n=== 训练LightGBM模型 ===")
model = lgb.train(
params,
train_data,
num_boost_round=1000,
valid_sets=[train_data, test_data],
callbacks=[
lgb.early_stopping(stopping_rounds=50),
lgb.log_evaluation(period=100)
]
)
# 特征重要性
print("\n=== 特征重要性 ===")
importance = model.feature_importance()
for feat, imp in sorted(zip(feature_cols, importance), key=lambda x: -x[1]):
print(f"{feat:15s}: {imp:.0f}")
# 计算IC(信息系数)
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
train_ic, _ = stats.pearsonr(train_pred, y_train)
test_ic, _ = stats.pearsonr(test_pred, y_test)
print(f"\n训练集IC: {train_ic:.4f}")
print(f"测试集IC: {test_ic:.4f}")2.3 生成每日预测信号
# 为每只股票生成每日预测
predictions = {}
for date in dates[25:-5]: # 跳过前25天(因子计算窗口)和最后5天(标签)
pred_date = {}
for code in stock_codes:
# 获取该日该股票的因子
mask = (factor_df['date'] == date) & (factor_df['stock'] == code)
if mask.sum() > 0:
features = factor_df.loc[mask, feature_cols].values[0]
pred = model.predict([features])[0]
pred_date[code] = pred
else:
pred_date[code] = np.nan
predictions[date] = pred_date
pred_df = pd.DataFrame(predictions).T
print(f"\n=== 预测信号生成完成 ===")
print(f"预测日期数: {len(pred_df)}")
print(f"信号范围: [{pred_df.min().min():.4f}, {pred_df.max().max():.4f}]")3. 组合构建
3.1 Top-K等权组合
def top_k_equal_weights(predictions, k=30):
"""
Top-K等权组合构建
选择预测值最高的K只股票,等权分配
"""
weights = pd.DataFrame(0, index=predictions.index, columns=predictions.columns)
for date in predictions.index:
daily_pred = predictions.loc[date].dropna()
if len(daily_pred) < k:
k = len(daily_pred)
# 选择预测值最高的K只
top_stocks = daily_pred.nlargest(k).index
# 等权分配
weights.loc[date, top_stocks] = 1 / k
return weights
# 构建Top30等权组合
top30_weights = top_k_equal_weights(pred_df, k=30)
print(f"\n=== Top30等权组合 ===")
print(f"平均持仓数量: {top30_weights.astype(bool).sum(axis=1).mean():.1f}")
print(f"平均单股权重: {(top30_weights.sum(axis=1) / top30_weights.astype(bool).sum(axis=1)).mean():.2%}")3.2 IC加权组合
def ic_weighted(predictions, top_p=0.3, power=2):
"""
IC加权组合
权重与预测值的幂次成正比
"""
weights = pd.DataFrame(0, index=predictions.index, columns=predictions.columns)
for date in predictions.index:
daily_pred = predictions.loc[date].dropna()
# 只选择预测值最高的部分
n_select = int(len(daily_pred) * top_p)
top_stocks = daily_pred.nlargest(n_select)
# IC加权:权重 = 预测值的绝对值^power
abs_pred = np.abs(top_stocks) ** power
w = abs_pred / abs_pred.sum()
# 加入方向
w = w * np.sign(top_stocks)
# 只保留正权重(做多)
w = w.clip(lower=0)
w = w / w.sum() if w.sum() > 0 else w
weights.loc[date, w.index] = w
return weights
# 构建IC加权组合
ic_weights = ic_weighted(pred_df, top_p=0.3, power=2)
print(f"\n=== IC加权组合 ===")
print(f"平均持仓数量: {ic_weights.astype(bool).sum(axis=1).mean():.1f}")
print(f"平均最大权重: {ic_weights.max(axis=1).mean():.2%}")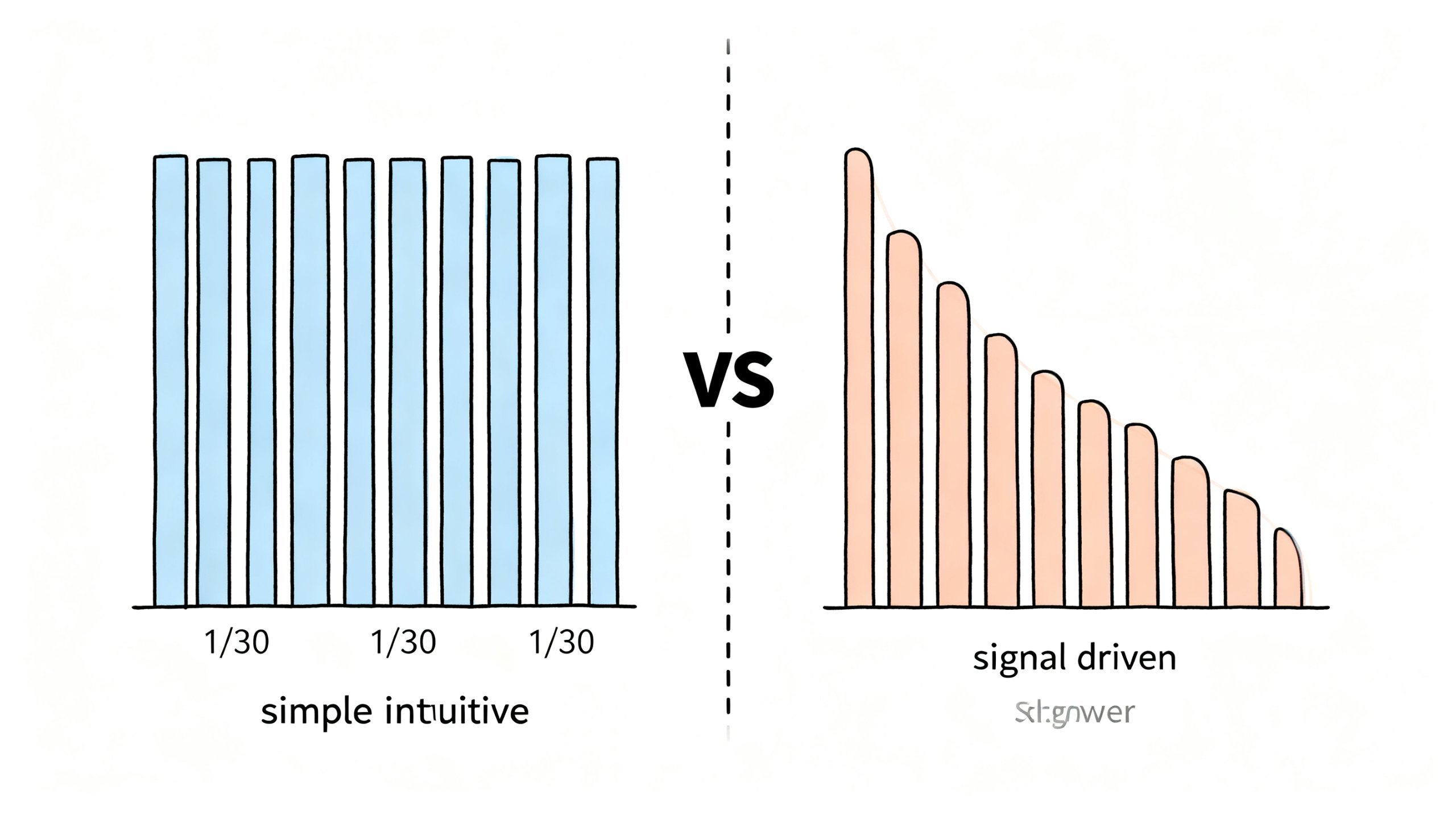
4. 执行模拟
4.1 交易成本模型
class TradingCost:
"""交易成本计算"""
def __init__(self):
self.commission_rate = 0.0003 # 万3
self.min_commission = 5 # 最低5元
self.stamp_duty_rate = 0.001 # 千1(卖出)
self.slippage_rate = 0.001 # 滑点0.1%
def calculate_buy_cost(self, trade_value):
"""计算买入成本"""
commission = max(trade_value * self.commission_rate, self.min_commission)
slippage = trade_value * self.slippage_rate
return commission + slippage
def calculate_sell_cost(self, trade_value):
"""计算卖出成本"""
commission = max(trade_value * self.commission_rate, self.min_commission)
stamp_duty = trade_value * self.stamp_duty_rate
slippage = trade_value * self.slippage_rate
return commission + stamp_duty + slippage
def get_total_rate(self):
"""获取双边总费率"""
buy_rate = self.commission_rate + self.slippage_rate
sell_rate = self.commission_rate + self.slippage_rate + self.stamp_duty_rate
return buy_rate + sell_rate
cost_model = TradingCost()
print(f"\n=== 交易成本 ===")
print(f"双边费率: {cost_model.get_total_rate():.4%}")4.2 回测引擎
def backtest(prices, weights, cost_model, initial_capital=1000000):
"""
完整回测
参数
----
prices : DataFrame
价格数据
weights : DataFrame
目标权重
cost_model : TradingCost
成本模型
initial_capital : float
初始资金
返回
----
result : dict
回测结果
"""
# 初始化
capital = initial_capital
position = pd.Series(0, index=weights.columns) # 当前持仓(股数)
cash = capital
portfolio_values = []
daily_returns = []
# 对齐日期
common_dates = weights.index.intersection(prices.index)
for i, date in enumerate(common_dates):
# T+1:今天的目标权重明天才能执行
if i == 0:
# 第一天按初始权重买入
target_weights = weights.loc[date]
else:
# 使用前一天的信号
target_weights = weights.loc[common_dates[i-1]]
current_prices = prices.loc[date]
# 计算当前组合价值
current_value = (position * current_prices).sum() + cash
# 记录
portfolio_values.append(current_value)
if i > 0:
daily_return = (current_value - portfolio_values[-2]) / portfolio_values[-2]
daily_returns.append(daily_return)
# 计算目标持仓
target_value = current_value
target_values = target_weights * target_value
target_shares = (target_values / current_prices).fillna(0)
# 计算需要调整的数量
trade_shares = target_shares - position
# 执行交易(考虑T+1,这里简化处理)
trade_values = trade_shares * current_prices
# 计算成本
buy_value = trade_values[trade_values > 0].sum()
sell_value = abs(trade_values[trade_values < 0]).sum()
buy_cost = cost_model.calculate_buy_cost(buy_value) if buy_value > 0 else 0
sell_cost = cost_model.calculate_sell_cost(sell_value) if sell_value > 0 else 0
total_cost = buy_cost + sell_cost
# 更新持仓
position = target_shares
cash = current_value - (position * current_prices).sum() - total_cost
# 计算最终统计
returns_series = pd.Series(daily_returns, index=common_dates[1:])
result = {
'portfolio_values': pd.Series(portfolio_values, index=common_dates),
'daily_returns': returns_series,
'final_value': portfolio_values[-1],
'total_return': (portfolio_values[-1] - initial_capital) / initial_capital,
'daily_returns_series': returns_series
}
return result4.3 运行回测
# 运行Top30等权回测
print("\n=== 运行Top30等权回测 ===")
top30_result = backtest(prices_data, top30_weights, cost_model)
# 运行IC加权回测
print("=== 运行IC加权回测 ===")
ic_result = backtest(prices_data, ic_weights, cost_model)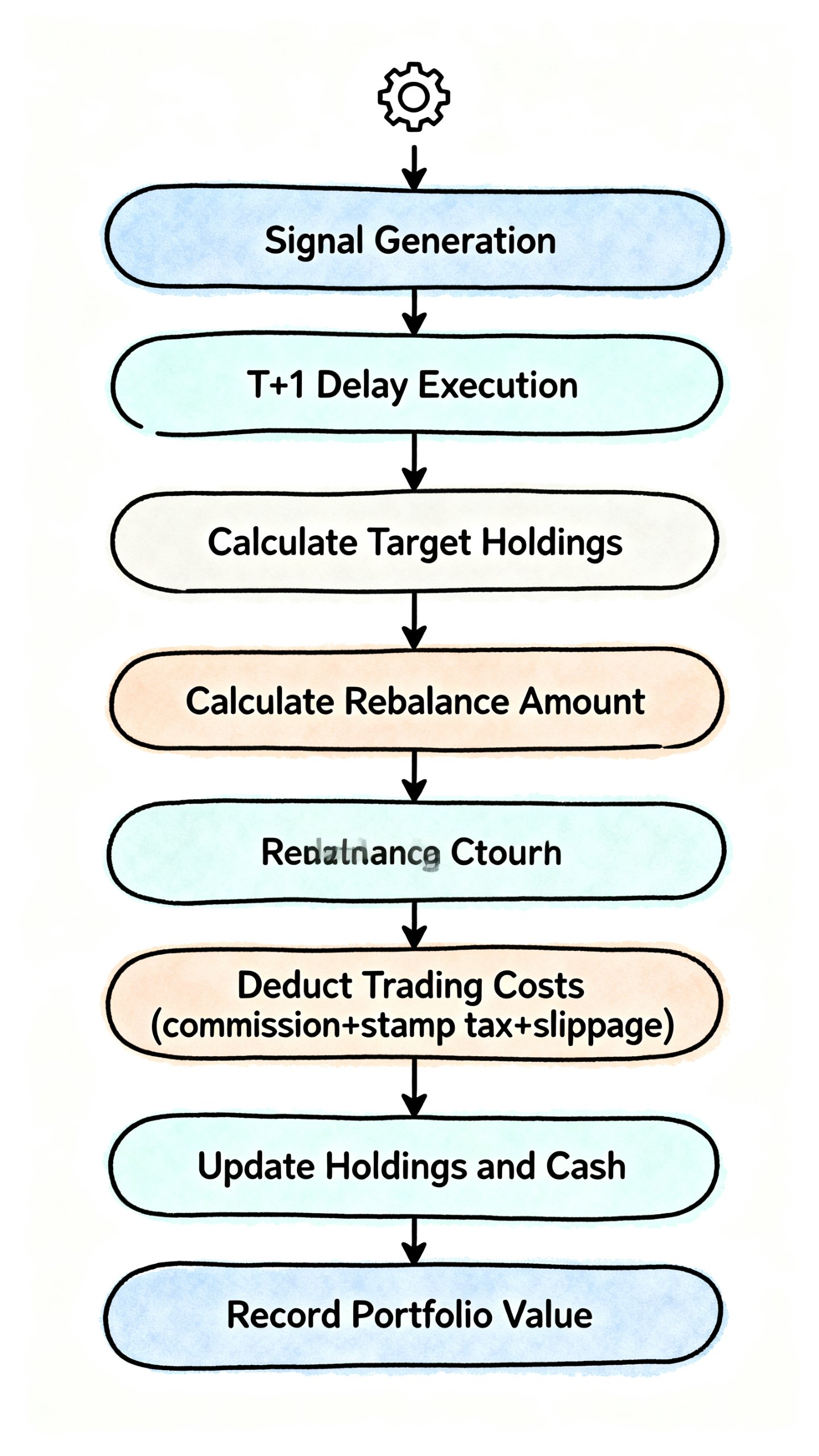
5. 绩效评估
5.1 计算绩效指标
def calculate_performance_metrics(result, benchmark_returns=None):
"""计算完整绩效指标"""
returns = result['daily_returns_series']
metrics = {}
# 收益指标
metrics['总收益率'] = result['total_return']
metrics['年化收益率'] = (1 + result['total_return']) ** (252 / len(returns)) - 1
# 风险指标
metrics['年化波动率'] = returns.std() * np.sqrt(252)
# 最大回撤
cumulative = (1 + returns).cumprod()
running_max = cumulative.expanding().max()
drawdown = (cumulative - running_max) / running_max
metrics['最大回撤'] = drawdown.min()
# Sharpe
excess_returns = returns - 0.03 / 252
metrics['Sharpe比率'] = excess_returns.mean() * 252 / (excess_returns.std() * np.sqrt(252))
# 胜率
metrics['胜率'] = (returns > 0).mean()
return metrics
# 计算两个策略的绩效
top30_metrics = calculate_performance_metrics(top30_result)
ic_metrics = calculate_performance_metrics(ic_result)
# 显示对比
print("\n" + "="*60)
print("策略绩效对比")
print("="*60)
comparison = pd.DataFrame({
'Top30等权': top30_metrics,
'IC加权': ic_metrics
})
print(comparison.map(lambda x: f"{x:.2%}" if isinstance(x, (int, float)) and abs(x) < 1 else f"{x:.4f}" if isinstance(x, float) else x))5.2 完整绩效报告
from scipy import stats
def generate_performance_report(result, name="策略"):
"""生成完整绩效报告"""
returns = result['daily_returns_series']
print(f"\n{'='*60}")
print(f"{name}绩效报告".center(50))
print('='*60)
# 基础统计
print(f"\n【收益指标】")
print(f" 总收益率: {result['total_return']:>10.2%}")
print(f" 年化收益率: {(1+result['total_return'])**(252/len(returns))-1:>10.2%}")
print(f"\n【风险指标】")
print(f" 年化波动率: {returns.std()*np.sqrt(252):>10.2%}")
print(f" 最大回撤: {(result['portfolio_values']/result['portfolio_values'].cummax()-1).min():>10.2%}")
# 风险调整收益
excess_returns = returns - 0.03/252
sharpe = excess_returns.mean()*252 / (returns.std()*np.sqrt(252))
print(f" Sharpe比率: {sharpe:>10.2f}")
# 交易统计
print(f"\n【交易统计】")
print(f" 胜率: {(returns>0).mean():>10.2%}")
print(f" 平均日收益: {returns.mean():>10.4%}")
print(f" 正收益均值: {returns[returns>0].mean():>10.4%}")
print(f" 负收益均值: {returns[returns<0].mean():>10.4%}")
# 分布特征
print(f"\n【收益分布】")
print(f" 偏度: {stats.skew(returns):>10.2f}")
print(f" 峰度: {stats.kurtosis(returns):>10.2f}")
generate_performance_report(top30_result, "Top30等权策略")
generate_performance_report(ic_result, "IC加权策略")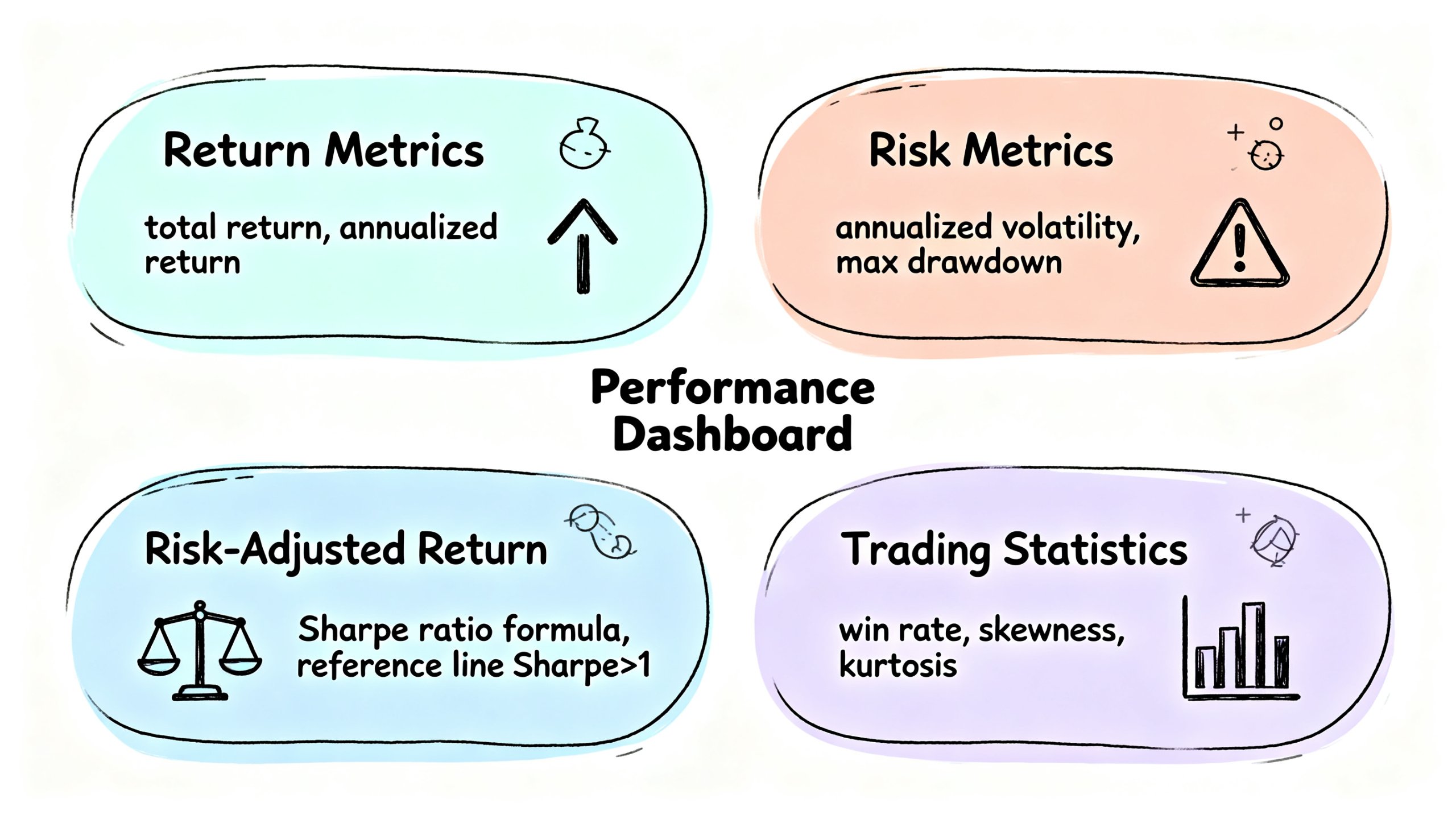
6. 可视化分析
6.1 累计收益曲线
plt.figure(figsize=(14, 6))
# 计算累计收益
top30_cum = (1 + top30_result['daily_returns_series']).cumprod()
ic_cum = (1 + ic_result['daily_returns_series']).cumprod()
plt.plot(top30_cum.index, top30_cum.values, label='Top30等权', linewidth=2)
plt.plot(ic_cum.index, ic_cum.values, label='IC加权', linewidth=2)
plt.title('累计收益曲线对比', fontsize=14, fontproperties='SimHei')
plt.xlabel('日期', fontproperties='SimHei')
plt.ylabel('累计收益', fontproperties='SimHei')
plt.legend(prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()6.2 回撤图
fig, axes = plt.subplots(2, 1, figsize=(14, 8))
# Top30等权回撤
top30_values = top30_result['portfolio_values']
top30_running_max = top30_values.cummax()
top30_drawdown = (top30_values - top30_running_max) / top30_running_max
axes[0].fill_between(top30_drawdown.index, top30_drawdown.values, 0,
color='red', alpha=0.3)
axes[0].plot(top30_drawdown.index, top30_drawdown.values, color='red', linewidth=1)
axes[0].set_title('Top30等权 - 回撤', fontproperties='SimHei', fontsize=12)
axes[0].grid(True, alpha=0.3)
# IC加权回撤
ic_values = ic_result['portfolio_values']
ic_running_max = ic_values.cummax()
ic_drawdown = (ic_values - ic_running_max) / ic_running_max
axes[1].fill_between(ic_drawdown.index, ic_drawdown.values, 0,
color='blue', alpha=0.3)
axes[1].plot(ic_drawdown.index, ic_drawdown.values, color='blue', linewidth=1)
axes[1].set_title('IC加权 - 回撤', fontproperties='SimHei', fontsize=12)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()6.3 月度收益热力图
def plot_monthly_returns(returns, ax=None, title="月度收益率"):
"""绘制月度收益热力图"""
monthly = returns.resample('M').apply(lambda x: (1+x).prod()-1)
monthly_df = pd.DataFrame({
'year': monthly.index.year,
'month': monthly.index.month,
'return': monthly.values
})
pivot = monthly_df.pivot(index='year', columns='month', values='return')
if ax is None:
fig, ax = plt.subplots(figsize=(12, 4))
im = ax.imshow(pivot.values, cmap='RdYlGn', aspect='auto',
vmin=-0.1, vmax=0.1)
ax.set_xticks(range(12))
ax.set_xticklabels(['1月','2月','3月','4月','5月','6月',
'7月','8月','9月','10月','11月','12月'])
ax.set_yticks(range(len(pivot.index)))
ax.set_yticklabels(pivot.index)
for i in range(len(pivot.index)):
for j in range(12):
text = ax.text(j, i, f'{pivot.values[i,j]:.1%}',
ha='center', va='center', fontsize=8)
ax.set_title(title, fontproperties='SimHei', fontsize=12)
plt.colorbar(im, ax=ax, label='收益率')
return ax
# 绘制Top30等权的月度收益
fig, axes = plt.subplots(2, 1, figsize=(12, 8))
plot_monthly_returns(top30_result['daily_returns_series'], axes[0], "Top30等权 - 月度收益率")
plot_monthly_returns(ic_result['daily_returns_series'], axes[1], "IC加权 - 月度收益率")
plt.tight_layout()
plt.show()7. 对比分析
7.1 忽略成本 vs 考虑成本
def backtest_no_cost(prices, weights, initial_capital=1000000):
"""不考虑成本的回测"""
capital = initial_capital
daily_returns = []
for i, date in enumerate(weights.index):
if i == 0:
target_weights = weights.loc[date]
else:
target_weights = weights.loc[weights.index[i-1]]
current_prices = prices.loc[date]
daily_return = (target_weights * current_prices.pct_change().fillna(0)).sum()
daily_returns.append(daily_return)
returns_series = pd.Series(daily_returns, index=weights.index)
return {
'daily_returns_series': returns_series,
'total_return': (1 + returns_series).prod() - 1
}
# 对比
top30_no_cost = backtest_no_cost(prices_data, top30_weights)
ic_no_cost = backtest_no_cost(prices_data, ic_weights)
print("\n=== 成本影响对比 ===")
print(f"{'策略':<15} {'无成本年化':<12} {'有成本年化':<12} {'成本拖累':<10}")
print('-'*60)
for name, no_cost, with_cost in [
('Top30等权', top30_no_cost, top30_result),
('IC加权', ic_no_cost, ic_result)
]:
no_cost_annual = (1 + no_cost['total_return']) ** (252/len(no_cost['daily_returns_series'])) - 1
with_cost_annual = (1 + with_cost['total_return']) ** (252/len(with_cost['daily_returns_series'])) - 1
drag = no_cost_annual - with_cost_annual
print(f"{name:<15} {no_cost_annual:>10.2%} {with_cost_annual:>10.2%} {drag:>8.2%}")7.2 不同调仓频率
def resample_weights(weights, freq):
"""降低调仓频率"""
return weights.resample(freq).ffill().reindex(weights.index).fillna(method='ffill')
# 测试不同频率
freqs = ['W', '2W', 'M'] # 周度、双周、月度
results_freq = {}
for freq in freqs:
print(f"\n测试调仓频率: {freq}")
resampled_weights = resample_weights(top30_weights, freq)
result = backtest(prices_data, resampled_weights, cost_model)
returns = result['daily_returns_series']
ann_return = (1 + result['total_return']) ** (252/len(returns)) - 1
ann_vol = returns.std() * np.sqrt(252)
sharpe = (returns.mean() * 252 - 0.03) / ann_vol
results_freq[freq] = {
'年化收益': ann_return,
'年化波动': ann_vol,
'Sharpe': sharpe
}
print(f" 年化收益: {ann_return:.2%}")
print(f" Sharpe: {sharpe:.2f}")
# 显示结果对比
freq_comparison = pd.DataFrame(results_freq).T
print("\n=== 调仓频率对比 ===")
print(freq_comparison)8. 完整代码汇总
"""
完整回测系统 - 代码汇总
将上述所有模块整合为一个完整的回测类
"""
class CompleteBacktestSystem:
"""完整的量化回测系统"""
def __init__(self, n_stocks=200, start_date='2021-01-01', end_date='2023-12-31'):
"""初始化回测系统"""
self.n_stocks = n_stocks
self.dates = pd.date_range(start_date, end_date, freq='B')
self.cost_model = TradingCost()
# 生成数据
self._generate_data()
def _generate_data(self):
"""生成模拟数据"""
np.random.seed(42)
# 生成股票代码
self.stock_codes = [f'S{i:04d}' for i in range(self.n_stocks)]
# 生成价格和收益率
self.returns_data = self._generate_returns()
self.prices_data = self._generate_prices()
self.volumes_data = self._generate_volumes()
# 生成因子
self.factors_dict, self.labels_dict = self._generate_factors_labels()
def _generate_returns(self):
"""生成收益率数据"""
# 简化实现
returns = pd.DataFrame(
np.random.randn(len(self.dates), self.n_stocks) * 0.02,
index=self.dates,
columns=self.stock_codes
)
return returns
def _generate_prices(self):
"""生成价格数据"""
initial_prices = np.random.uniform(10, 100, self.n_stocks)
prices = pd.DataFrame(0, index=self.dates, columns=self.stock_codes)
for i, code in enumerate(self.stock_codes):
prices[code] = initial_prices[i] * (1 + self.returns_data[code]).cumprod()
return prices
def _generate_volumes(self):
"""生成成交量数据"""
return pd.DataFrame(
np.random.lognormal(16, 0.5, (len(self.dates), self.n_stocks)).astype(int),
index=self.dates,
columns=self.stock_codes
)
def _generate_factors_labels(self):
"""生成因子和标签"""
factors = {}
labels = {}
for code in self.stock_codes:
df = pd.DataFrame({
'momentum': self.prices_data[code].pct_change(20),
'volatility': self.returns_data[code].rolling(20).std(),
'label': self.returns_data[code].shift(-5)
}, index=self.dates)
factors[code] = df
labels[code] = df['label']
return factors, labels
def train_model(self):
"""训练预测模型"""
# 准备数据
all_data = []
for code in self.stock_codes:
df = self.factors_dict[code].copy()
df['stock'] = code
all_data.append(df)
factor_df = pd.concat(all_data).dropna()
# 划分训练测试
train = factor_df[factor_df.index < '2023-01-01']
test = factor_df[factor_df.index >= '2023-01-01']
# 训练模型(简化)
self.model = None # 这里应该是实际的模型训练
return train, test
def run_backtest(self, method='topk', **params):
"""
运行回测
参数
----
method : str
'topk' - TopK等权
'ic' - IC加权
**params :
方法相关参数
"""
# 生成预测信号(简化)
predictions = pd.DataFrame(
np.random.randn(len(self.dates), self.n_stocks),
index=self.dates,
columns=self.stock_codes
)
# 构建组合
if method == 'topk':
k = params.get('k', 30)
weights = top_k_equal_weights(predictions, k)
elif method == 'ic':
weights = ic_weighted(predictions, **params)
# 运行回测
result = backtest(self.prices_data, weights, self.cost_model)
return result
# 使用示例
system = CompleteBacktestSystem()
result = system.run_backtest(method='topk', k=30)9. 结果解读与优化方向
结果解读要点
-
收益来源分析
- 是选股能力还是择时能力?
- 哪些股票贡献最大?
-
风险分析
- 最大回撤发生在什么时期?
- 是否有集中持仓风险?
-
成本分析
- 换手率是否过高?
- 交易成本占比多少?
常见优化方向
| 优化方向 | 具体方法 |
|---|---|
| 信号质量 | 添加更多因子、特征工程 |
| 组合构建 | 行业中性、风险控制 |
| 执行优化 | 算法交易、分批成交 |
| 成本控制 | 降低调仓频率、设置阈值 |
10. 总结
本案例涵盖的知识点
┌────────────────────────────────────────────────────────────────┐
│ 实战案例知识体系 │
├────────────────────────────────────────────────────────────────┤
│ │
│ ✓ 数据生成与处理 │
│ ✓ Alpha模型训练 │
│ ✓ 组合构建方法 │
│ ✓ 交易成本建模 │
│ ✓ 完整回测执行 │
│ ✓ 绩效评估指标 │
│ ✓ 可视化分析 │
│ ✓ 对比分析 │
│ │
└────────────────────────────────────────────────────────────────┘
下一步建议
- 实盘验证:在模拟盘中测试策略
- 参数优化:系统性地测试不同参数组合
- 风险管理:添加止损、仓位限制
- 持续监控:定期评估策略表现
核心知识点总结
┌────────────────────────────────────────────────────────────────┐
│ 06-实战案例 核心要点 │
├────────────────────────────────────────────────────────────────┤
│ │
│ 完整回测流程 │
│ 数据 → 因子 → 模型 → 信号 → 组合 → 执行 → 评估 │
│ │
│ 关键实践要点 │
│ ├─ 数据质量决定回测质量 │
│ ├─ 模型IC值 > 0.03 才有使用价值 │
│ ├─ 组合构建需要考虑换手率 │
│ ├─ 交易成本可能吞噬收益 │
│ └─ 绩效评估要全面,不只看收益 │
│ │
│ 对比分析要点 │
│ ├─ Top-K等权 vs IC加权 │
│ ├─ 考虑成本 vs 忽略成本 │
│ └─ 不同调仓频率的影响 │
│ │
└────────────────────────────────────────────────────────────────┘
结语
恭喜你完成了回测方法论模块的学习!
现在你应该能够:
- ✅ 理解回测的基本原理和流程
- ✅ 从信号构建投资组合
- ✅ 准确建模交易成本
- ✅ 计算和解读各类绩效指标
- ✅ 识别和防范回测陷阱
- ✅ 独立完成完整的回测项目
记住:回测的目的是发现问题,而不是证明策略有效。保持批判性思维,你的实盘交易会更加稳健!
思考与实践
- 尝试修改案例中的参数,观察结果变化
- 添加新的因子,看是否能提升模型IC
- 实现均值方差优化的组合构建方法
- 将本模块的代码应用到真实数据上